5. ウェブとグラフ#
5.1. ウェブ#
ウェブ(World wide web; Web) は,インターネット上に構築されたハイパーテキスト(hypertext) システムである. ハイパーテキストとは文書同士をハイパーリンク(単にリンクと呼ぶことも)をつなぐ仕組みである. 勘違いされやすいが,インターネットは通信網であって「インターネット = ウェブ」ではない.
ウェブはウェブページをノード,リンクをエッジと見れば,グラフと見なすことができる(より厳密には有向グラフである). ウェブページは数100億,ウェブページ間のリンクは数兆あると言われており,ウェブは社会に存在する最も巨大なグラフと言える.

ウェブには,玉石混淆ではあるが,様々なトピックに関するウェブページが日々アップロードされている. 今日,ウェブは貴重な知識源の1つであることに異論はないであろう. そのようなウェブからウェブページを見つけるためのツールが検索エンジンである.
検索エンジンは,日々リンクを辿ってウェブページを巡回し,データベースに格納し,検索のための索引づけを行っている. 伝統的な検索エンジンは,検索ワードと文書との関連性をランキング指標として,データベースに格納された文書をランキングしていた. 検索ワードと文書の関連性は,直感的には「検索ワードに関連した語がどの程度出現するか」で評価される.
検索対象となるウェブページ数が少ない場合,検索ワードとの関連性でウェブページを評価する方法でも良い. しかし,ウェブページは膨大にあるため,検索ワードの関連性だけでは有用なウェブページを絞りきれない. また,検索ワードとして入力そうな語をウェブページにたくさん入れておけば,ランキングを上げることもできてしまう. そのため,検索ワードに対する関連性以外の観点からも,ウェブページの重要度を評価する方法が必要となる.
以降で説明するPageRankとHITSは,ウェブのグラフとして特徴を活かし,ウェブページの重要性を評価するウェブ黎明期に発表された重要なアルゴリズムである. これらアルゴリズムが発表されて以降,これらアルゴリズムを改善,発展させたアルゴリズムが多数登場している.
5.2. PageRank#
PageRankはGoogleの創業者であるSergey BrinとLarry Pageが提案したアルゴリズムである. Googleの検索エンジンはPageRankの実装により,ウェブ検索エンジンのトップランナーに躍り出た.
PageRankはウェブページに張られたリンクを一種の「投票」と見なし,ウェブページの重要度(PageRank値)を計算する. PageRankは,重要度の計算のために,以下のような仮定を置く.
多くの重要なウェブページからリンクされたウェブページほど重要である
ご覧の通り,この仮定は再帰的(堂々巡り)であるが,実際の計算ではどう対応するのであろうか.
5.2.1. 単純なPageRank#
シンプルなPageRankアルゴリズムは,以下の手順でウェブページの重要度を計算する:
計算対象とするウェブページ群\(W\)を用意する(ウェブページはN個あるとする)
各ウェブページ\(w \in W\)のPageRank値\(p(w)\)を\(\frac{1}{N}\)で初期化する
ウェブページ\(w\)にリンクするウェブページ集合を\(W_{to}(w)\)とする.このとき,すべてのウェブページのPageRank値を以下の式で更新する.なお,ウェブページ\(w\)のPageRank値の初期値は\(p_0(w)\)に対応する.また,\(deg_{out}(w)\)はウェブページ\(w\)の出次数を表す.
PageRank値が収束するまで,ステップ3の処理を繰り返す.
上記手順について,下記グラフ\(G\)を用いて具体的に考えてみよう.
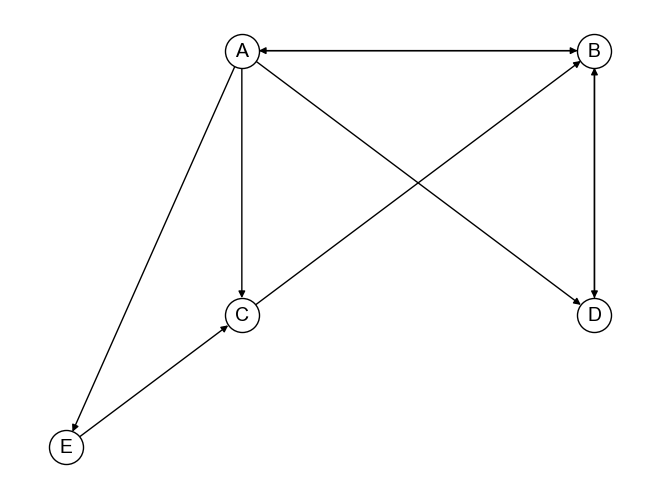
まず,PageRank値を初期化する. 上記グラフ\(G\)はノード数が5であるため,どのノードもPageRankの初期値は\(\frac{1}{5}\)となる.
次のステップでは,PageRank値を更新する. ここでは,ノードDのPageRank値を更新することを考えてみよう. ノードDはノードAとノードBからリンクされている. よって,更新式に従うと,ノードDのPageRank値はノードAとノードBのPageRank値によって更新される.
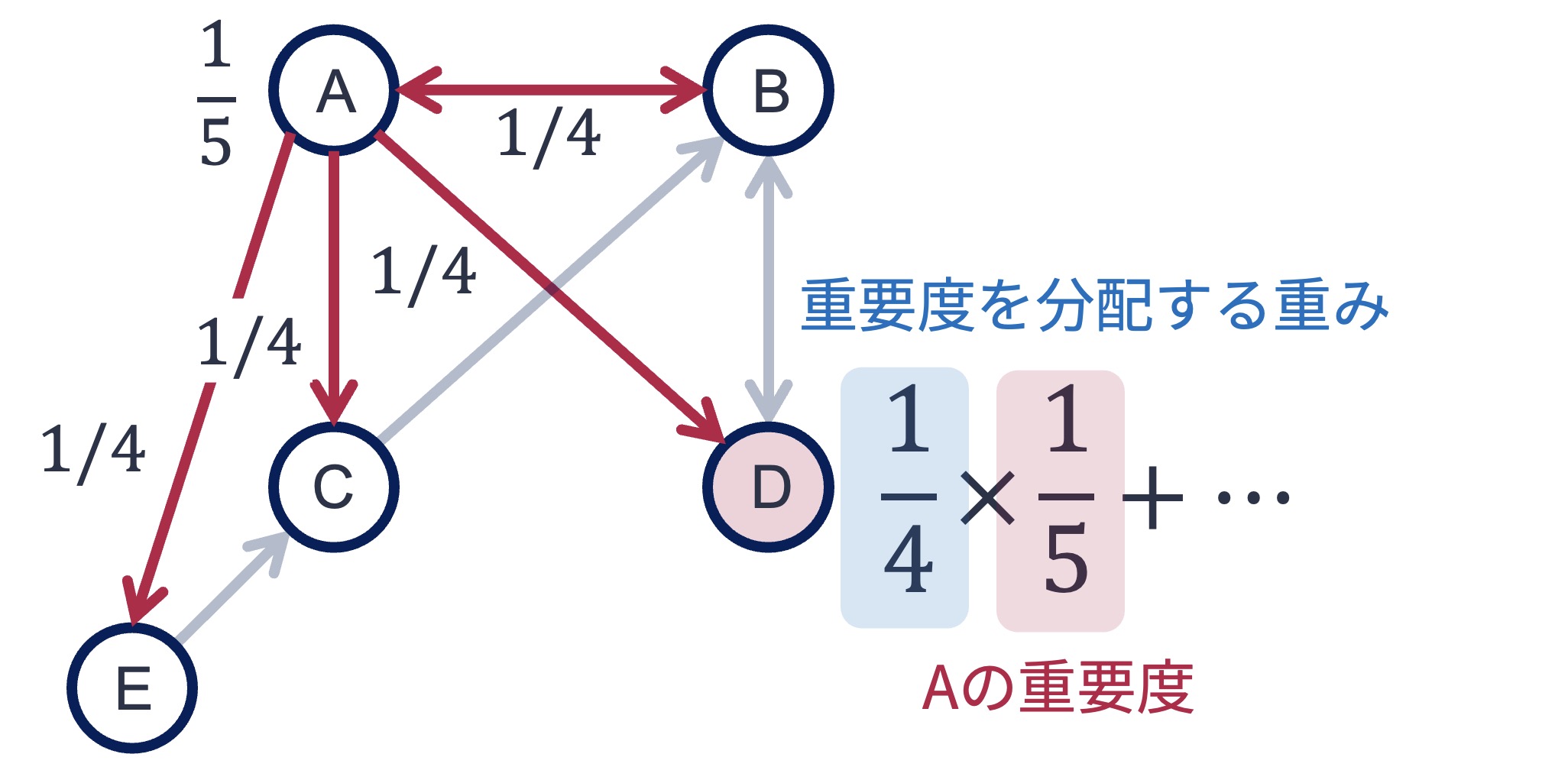
現時点でのノードAのPageRank値は\(\frac{1}{5}\)である. また,上図のように,ノードAはB,C,D,Eの4つのノードにリンクを張っている. それゆえ,更新式に従うと,ノードDにはノードAのもつPageRank値(\(=\frac{1}{5}\))の\(\frac{1}{4}\)が配分される. 同様に,ノードBからもノードDに\(\frac{1}{2} \times \frac{1}{5}\)のPageRank値が配分される. この配分によって,ノードDのPageRank値は
と更新される. 他のノードも同様の処理を行うと,1回目の更新で以下のようになる.
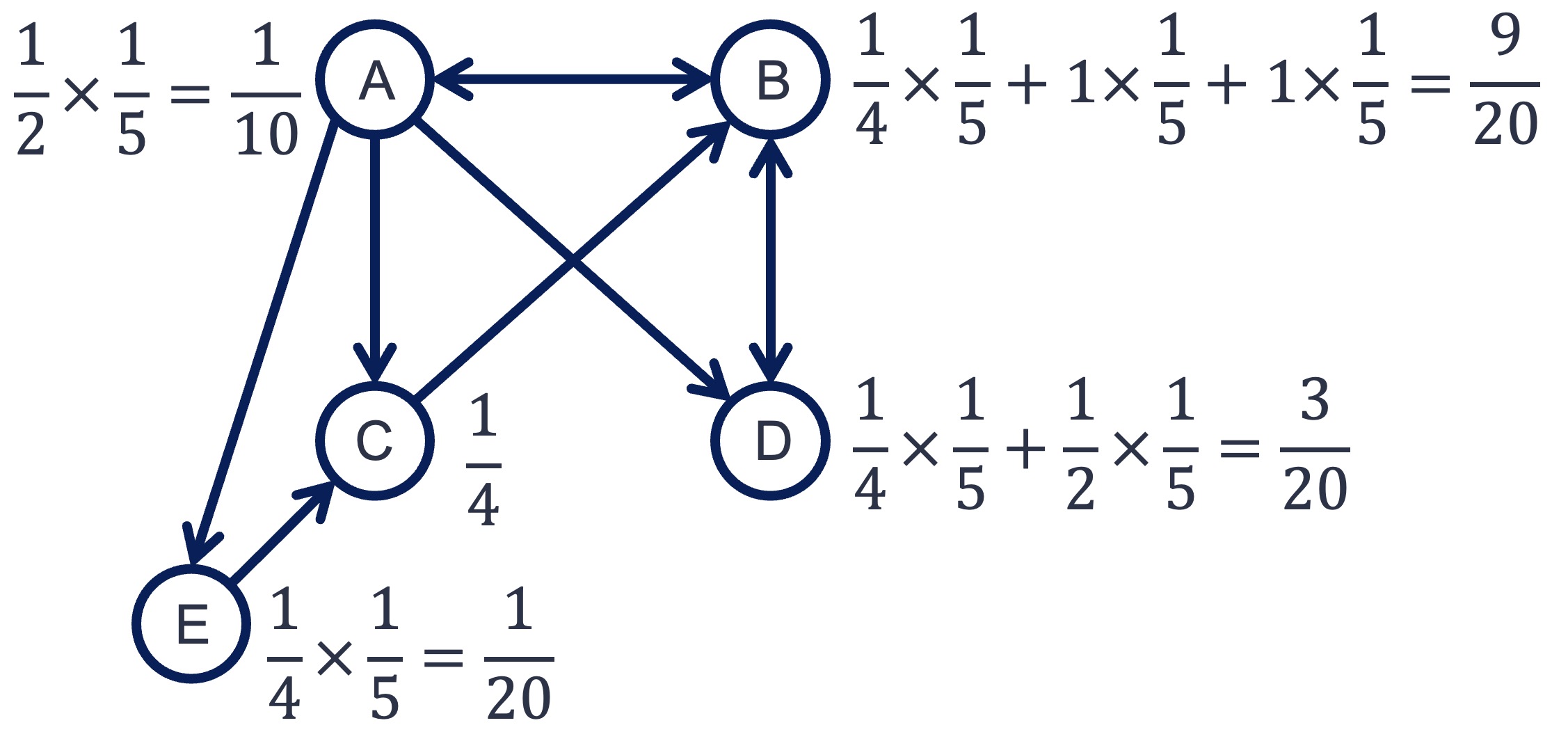
この処理について,すべてのノードのPageRank値が収束するまで繰り返す. 値は徐々に変化しなくなり,最終的には以下のように落ち着く. 収束したときの値が,最終的なPageRank値となる.
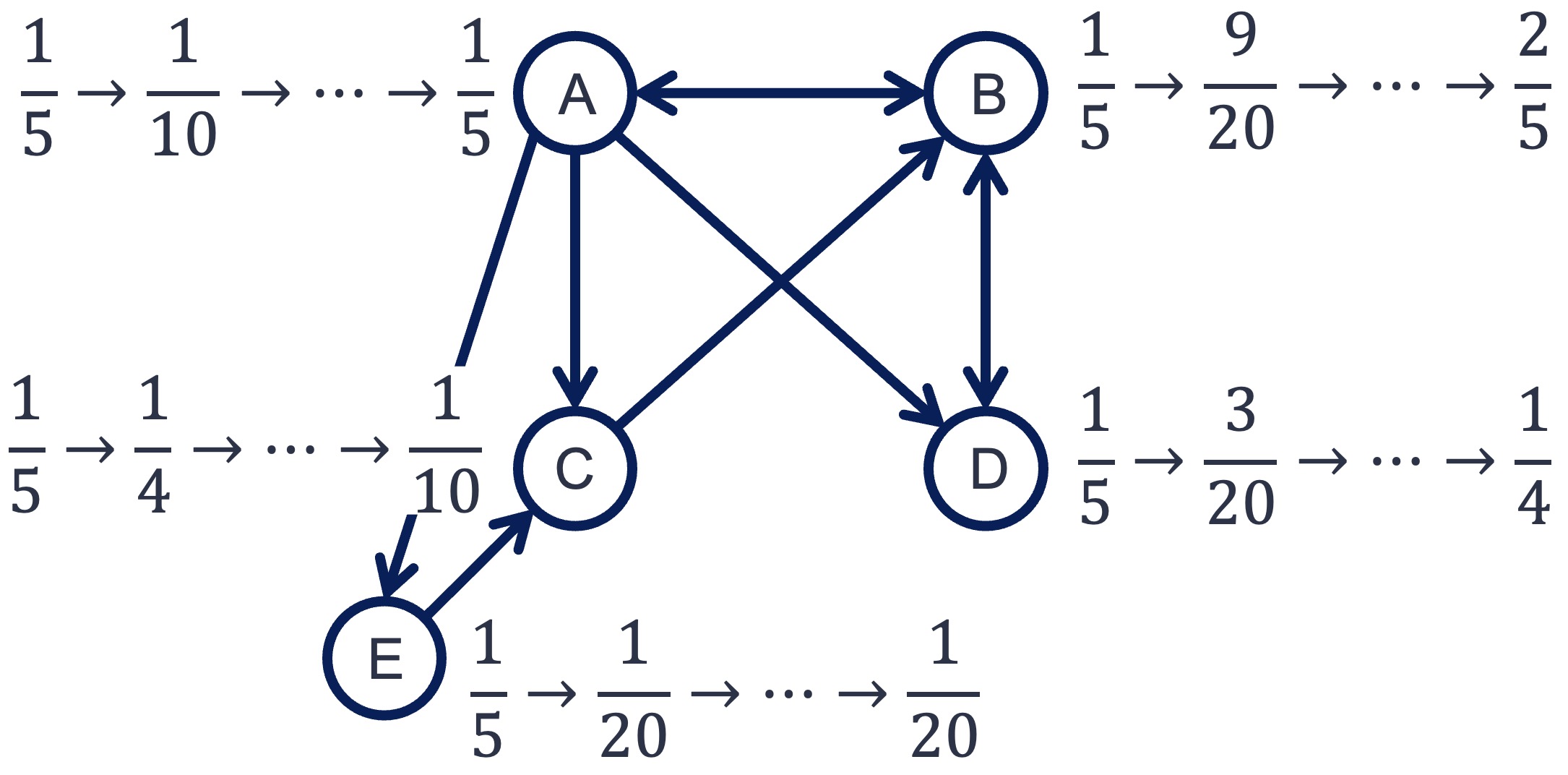
以上が単純なPageRankの計算手順であるが,行列を用いると計算を効率よく行える. 以下は,上で説明したPageRankの計算手順を行列を用いて書き直したものである.
計算対象とするウェブページ群\(W\)を,その隣接行列を\(\boldsymbol{A}\)とする.また,隣接行列\(\boldsymbol{A}\)の各行の値を行の値の合計値で正規化した行列を\(\boldsymbol{M}\)とする(遷移確率行列).
各ウェブページのPageRank値を格納したベクトルを\(\boldsymbol{p}\)とし,その要素値を\(\frac{1}{N}\)で初期化する(\(N\)はウェブページの数).
以下の式でPageRankベクトルを更新する(\(\boldsymbol{p}_{0}\)が初期値となる)
PageRank値が収束するまで,ステップ3の処理を繰り返す.
NumPyを用いれば,上記PageRankの計算手順は簡単に書ける. 以下は,例で用いたグラフ\(G\)の各ノードのPageRank値を求めるPythonコードである.
import networkx as nx
import numpy as np
# 行列の正規化のために使う
from sklearn.preprocessing import normalize
# グラフの定義
G = nx.DiGraph([
('A', 'B'), ('A', 'C'), ('A', 'D'), ('A', 'E'),
('B', 'A'), ('B', 'D'),
('C', 'B'),
('D', 'B'),
('E', 'C')
])
# PageRankベクトルを初期化する
N = G.number_of_nodes()
p = np.ones(N).reshape(-1, 1) # 要素値1,要素数がNの縦ベクトル
p = p / N
# 隣接行列
A = nx.adjacency_matrix(G).toarray()
# 遷移確率行列
M = normalize(A, norm='l1', axis=1)
# PageRank値の更新.100回繰り返せば値は収束する
for i in range(100):
p = np.dot(M.T, p)
p
array([[0.2 ],
[0.4 ],
[0.1 ],
[0.25],
[0.05]])
上記のPageRankはシンプルであり役に立ちそうだが,この方法を用いてもウェブページの重要度を計算できない. ウェブグラフ中に,以下のようなデッドエンドやスパイダーとラップと呼ばれる構造を含んでいると,PageRankが意図しない値に収束してしまうのである. この問題を解決するために,オリジナルのPageRankアルゴリズムは一工夫をしている.
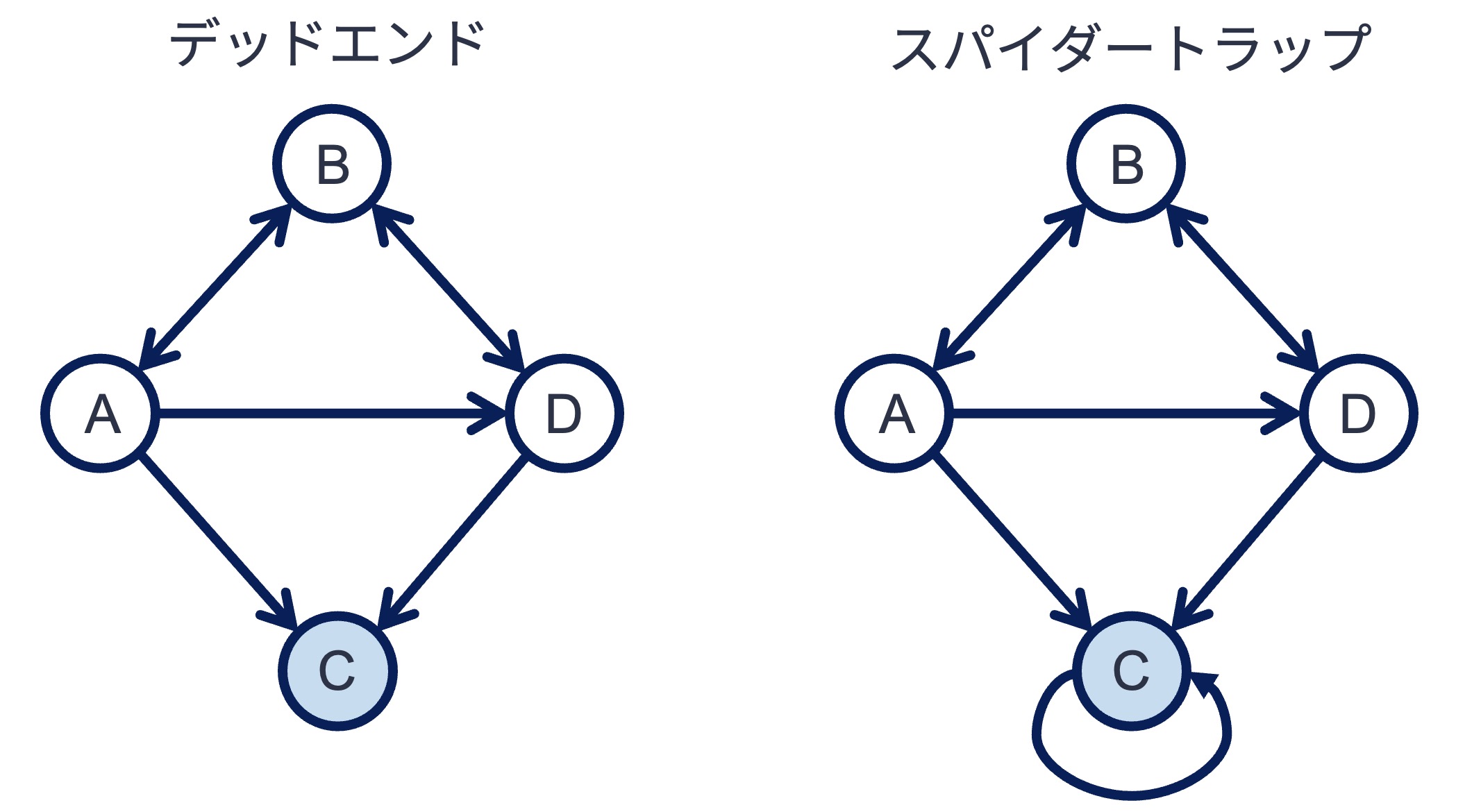
5.2.2. 完全なPageRank#
デッドエンド問題やスパイダートラップ問題を解決するために,オリジナルのPageRankアルゴリズムではランダムサーファーモデル(random surfer model) という仮定を導入している. あなたがウェブブラウジングをしている時を想像してほしい. ブラウジングをする際,ウェブページ内のリンクをクリックして別のページに移動することもあれば,ブックマークやQRコードなどURLを直接指定して(リンクを辿らず)ウェブページに飛ぶこともあるだろう. ランダムサーファーモデルとは,ユーザは「リンクによるページ移動」と「直接ページ移動(ジャンプ)」を切り替えながらページを移動する,という仮定である. この仮定を反映するようにシンプルなPageRankを修正することで,ウェブグラフ中にどんな構造があっても
多くの重要なウェブページからリンクされたウェブページほど重要である
という仮定を踏まえたPageRank値を計算することが可能となる.
以下,修正を施した完全なPageRank値を計算手順である.
計算対象とするウェブページ群\(W\)を,その隣接行列を\(\boldsymbol{A}\)とする.また,隣接行列\(\boldsymbol{A}\)の各行の値を行の値の合計値で正規化した行列を\(\boldsymbol{M}\)とする(遷移確率行列).
各ウェブページのPageRank値を格納した縦ベクトルを\(\boldsymbol{p}\)とし,その要素値を\(\frac{1}{N}\)で初期化する(\(N\)はウェブページの数).
以下の式でPageRankベクトルを更新する.なお,\(\alpha\)は事前に指定した定数である.また,\(\boldsymbol{e}\)は要素数が\(N\),要素が1の縦ベクトルである.
PageRank値が収束するまで,ステップ3の処理を繰り返す.
シンプルなPageRankとの違いはステップ3の更新式である. 式中の\(\boldsymbol{M}^T \boldsymbol{p}_{n}\)は「リンクを辿る行動」によるPageRank値の更新に対応する. 一方,\(\frac{\boldsymbol{e}}{N}\)は「リンクを辿らず,直接ページを訪問する行動」によるPageRank値の更新に対応し,どのページにも同じ確率で(ランダムに)ジャンプすることを想定している. 第1項の前にかかっている\(\alpha\)は,リンクを辿る行動を\(\alpha\)の確率で選択することを意味している.
Networkxライブラリには,PageRank値を計算する関数pagerankが実装されている.
以下は,上で挙げたスパイダートラップ構造を持つグラフのPageRank値を\(\alpha=0.85\)の設定で計算するコード例である.
# グラフの定義
G_spidertrap = nx.DiGraph([
('A', 'B'), ('A', 'C'), ('A', 'D'),
('B', 'A'), ('B', 'D'),
('C', 'C'),
('D', 'C'),
])
nx.pagerank(G_spidertrap, alpha=0.85, max_iter=100)
{'A': 0.06075345057192806,
'B': 0.05471356944165799,
'C': 0.8065659599728277,
'D': 0.07796702001358605}
5.3. HITS#
HITS(hypertext induced topic search) アルゴリズムは,PageRankとほぼ同じ時期に提案されたウェブページの重要度を測るアルゴリズムである. PageRankと同じく,ウェブページ間のリンク構造に着目したアルゴリズムであるが,趣が異なる.
HITSは,ウェブページの役割には2種類あると仮定している. 1つはオーソリティ(authority) としての役割である. 特定のトピックに対して重要な情報を載せているウェブページは,同様のトピックを扱うページからも多く参照されるはずである. このようなページはオーソリティ的な役割を果たしている. 例えば,著名な専門家が書いたウェブページが該当する.
2つ目はハブ(hub) としての役割である. ウェブページの中には,自身のページには重要な情報を掲載していないが,重要な情報を掲載したウェブページ,すなわちオーソリティ的なページへのリンクをまとめているものがある. このようなページはハブ的な役割を果たしている. リンク集サイトなどがハブ的なページに該当する.
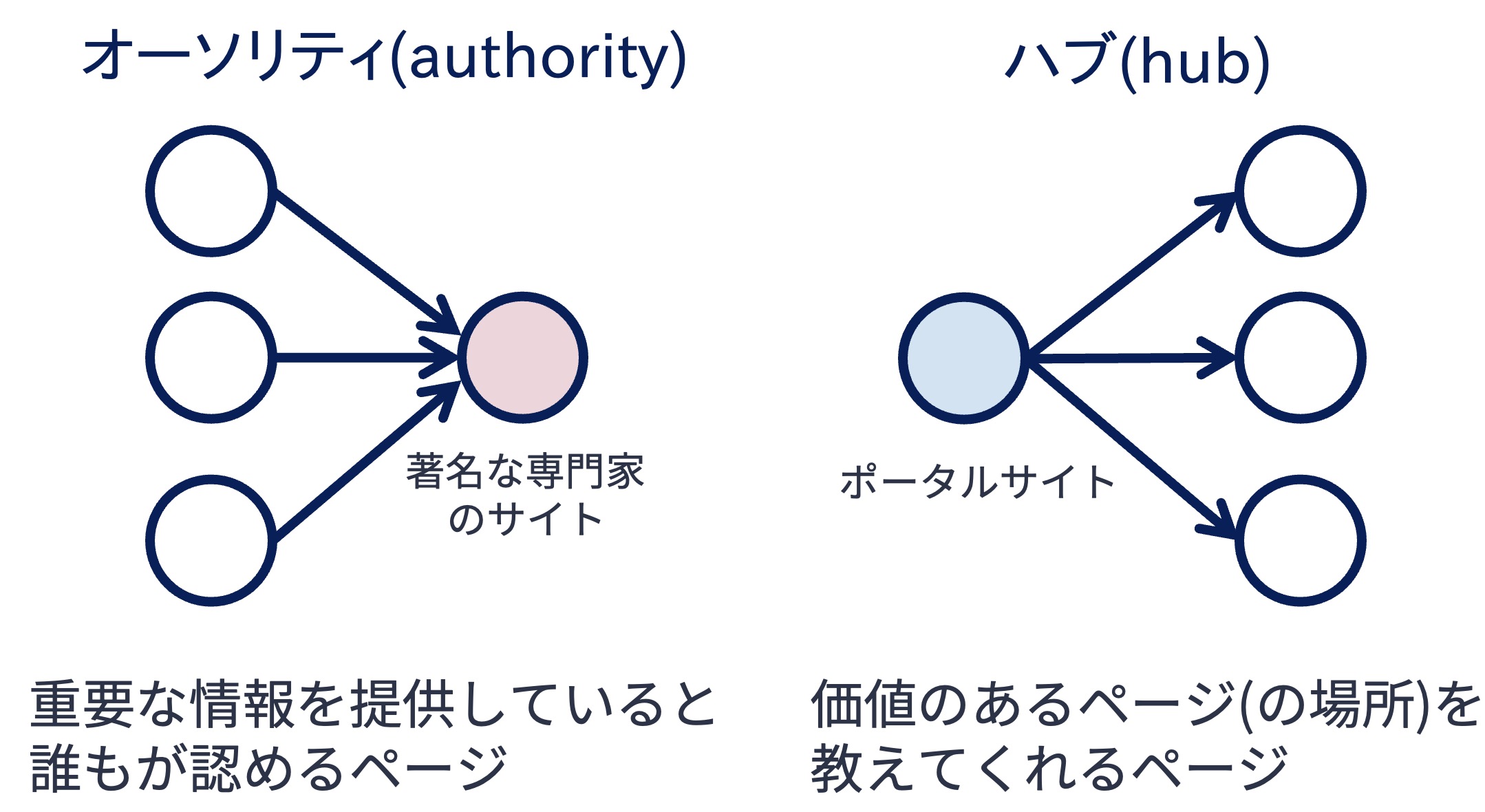
HITSはウェブページのオーソリティとしての良さ,ハブとしての良さを計算するアルゴリズムである. HITSは計算のために,以下の仮定を置いている:
ハブ値が高いページから多く参照されているページはオーソリティ値が高い
オーソリティ値が高いページを多く参照しているページはハブ値が高い
PageRankと同様,HITSアルゴリズムも再帰的な仮定を置いている. この仮定をもとに,HITSは以下の手順でウェブページの重要度(すなわち,オーソリティ値とハブ値)を計算する:
計算対象とするウェブページ群\(W\)を用意する(ウェブページはN個あるとする)
各ウェブページ\(w \in W\)のハブ値\(hub(w)\)およびオーソリティ値\(auth(w)\)を1で初期化する
ウェブページ\(w\)にリンクするウェブページ集合を\(W_{to}(w)\),ウェブページ\(w\)からリンクされたウェブページ集合を\(W_{from}(w)\)とする.このとき,すべてのウェブページのオーソリティ値,ハブ値を以下の式で更新する:
更新したハブ値,オーソリティ値を合計値で正規化する.
ハブ値,オーソリティ値が収束するまで,ステップ3-4の処理を繰り返す.
5.3.1. HITSアルゴリズムの行列表現#
上記の計算手順は,行列を使うとスマートかつ効率的に計算することができる. 以下,行列を使った計算手順である:
計算対象とするウェブページ群\(W\)を用意する(ウェブページはN個あるとする).
各ウェブページのハブ値およびオーソリティを格納したベクトルをそれぞれ\(\boldsymbol{h}\),\(\boldsymbol{a}\)とし,各ベクトルの要素値を1で初期化する.
ウェブグラフの隣接行列を\(\boldsymbol{A}\)する.このとき,すべてのウェブページのオーソリティ値,ハブ値を格納したベクトルを以下の式で更新する.なお,\(\boldsymbol{h}_0\),\(\boldsymbol{a}_0\)はハブベクトル,オーソリティベクトルの初期値である:
更新したハブベクトル,オーソリティベクトルをL1ノルムで正規化する.
ハブ値,オーソリティ値が収束するまで,ステップ3-4の処理を繰り返す.
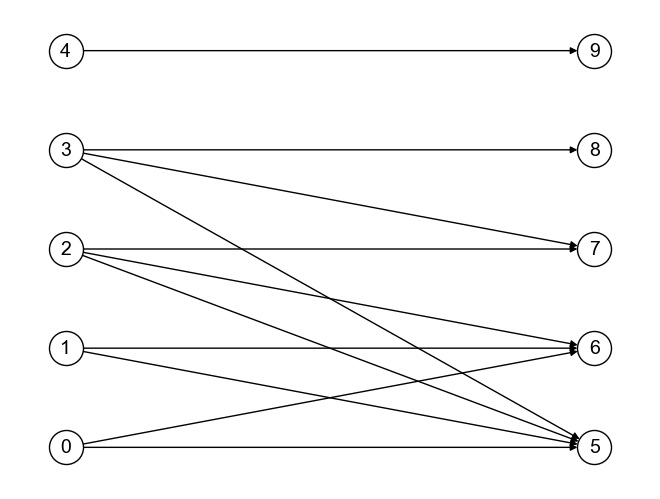
上記グラフ\(G_{bipartite}\)に対して,HITSアルゴリズムを具体的に実行してみよう. グラフ\(G_{bipartite}\)の各ノードのハブ値,オーソリティ値を求めるPythonコードは,以下のように書ける.
import networkx as np
import numpy as np
from sklearn.preprocessing import normalize
# グラフを定義
G_bipartite = nx.DiGraph()
G_bipartite.add_nodes_from([0, 1, 2, 3, 4], bipartite=0)
G_bipartite.add_nodes_from([5, 6, 7, 8, 9], bipartite=1)
G_bipartite.add_edges_from([
(0, 5), (0, 6),
(1, 5), (1, 6),
(2, 5), (2, 6), (2, 7),
(3, 5), (3, 7), (3, 8),
(4, 9)
])
# グラフ中のノード数
N = G_bipartite.number_of_nodes()
# 隣接行列を取得
A = nx.adjacency_matrix(G_bipartite).toarray()
# ハブ値ベクトルを初期化
h = np.ones(N).reshape(-1, 1)
# オーソリティ値ベクトルを初期化
a = np.ones(N).reshape(-1, 1)
# ハブ値,オーソリティ値の更新(100回繰り返せば十分に収束する)
for i in range(100):
a_new = np.dot(A.T, h)
h_new = np.dot(A, a)
# L1正規化
a = normalize(a_new, norm='l1', axis=0)
h = normalize(h_new, norm='l1', axis=0)
h, a
(array([[2.32408121e-01],
[2.32408121e-01],
[3.02775638e-01],
[2.32408121e-01],
[2.22745517e-45],
[0.00000000e+00],
[0.00000000e+00],
[0.00000000e+00],
[0.00000000e+00],
[0.00000000e+00]]),
array([[0.00000000e+00],
[0.00000000e+00],
[0.00000000e+00],
[0.00000000e+00],
[0.00000000e+00],
[3.94448725e-01],
[3.02775638e-01],
[2.11102551e-01],
[9.16730868e-02],
[2.63585055e-45]]))
PageRankと同様,HITSアルゴリズムもNetworkxライブラリにhits関数と名前で実装されている.
HITSを用いてハブ値,オーソリティ値を計算したい場合,以下のコードを実行すればよい.
h, a = nx.hits(G_bipartite)
h, a
({0: 0.2324081207560018,
1: 0.2324081207560018,
2: 0.3027756377319947,
3: 0.2324081207560018,
4: -0.0,
5: -0.0,
6: -0.0,
7: -0.0,
8: -0.0,
9: -0.0},
{0: -0.0,
1: -0.0,
2: -0.0,
3: -0.0,
4: -0.0,
5: 0.3944487245360107,
6: 0.30277563773199473,
7: 0.21110255092797858,
8: 0.09167308680401606,
9: -0.0})
5.4. クイズ#
5.4.1. Q1: デッドリンク,スパイダートラップのあるグラフ#
上記の各グラフに対してシンプルなPageRankアルゴリズムを適用すると,どのような値に収束するか. Pythonコードを書いて確かめなさい.
import networkx as nx
# グラフの定義
G_deadend = nx.DiGraph([
('A', 'B'), ('A', 'C'), ('A', 'D'),
('B', 'A'), ('B', 'D'),
('D', 'B'),
])
G_spidertrap = nx.DiGraph([
('A', 'B'), ('A', 'C'), ('A', 'D'),
('B', 'A'), ('B', 'D'),
('C', 'C'), ('D', 'B'),
])
# Write your codes below
5.4.2. Q2: PageRank実装#
NetworkXのpagerank関数を用いずに,(完全な)PageRank値を計算する関数calc_pagerankを実装しなさい.
なお,calc_pagerank関数の引数は以下としなさい:
第1引数: NetworkX形式のグラフ\(G\)
第2引数: \(\alpha\)パラメータ.デフォルト値は0.85
第3引数: 更新回数.デフォルト値は50
5.4.3. Q3: 江戸時代の人物#
コチラからダウンロードできるファイル(edo.gml)は,Wikipediaの江戸時代の人物一覧に掲載された歴史上の人物をノード,人物記事から人物記事へのリンクをエッジとするグラフデータを格納したものである.
例えば,江戸時代の人物一覧に掲載されている徳川家康の記事には,同じく江戸時代の人物一覧に掲載された伊達政宗への記事へのリンクが存在するため,グラフ中では徳川家康ノードから伊達政宗ノードへエッジが存在する.
※ 江戸時代に活躍した人物でも江戸時代の人物一覧に掲載されていない人物も存在する.例えば,坂本龍馬は幕末の人物一覧には掲載されているが,江戸時代の人物一覧には掲載されていない.

上のグラフ\(G_{edo}\)は,ダウンロードしたファイルedo.gmlをNetworkXで読み込み,可視化したものである.
グラフ\(G_{edo}\)にPageRankアルゴリズムを適用し,江戸時代の人物のPageRankスコア上位30名を求めなさい.
なお,コチラからダウンロードしたファイルedo.gmlをNetworkXで読み込むには,以下のコードを実行するとよい.
# ダウンロードしたファイルは`data/edo.gml`にあるとする(ファイルの保存先はどこでもよい)
G_edo = nx.read_gml("data/edo.gml")
5.4.4. Q4: Biased PageRank#
オリジナルのPageRankアルゴリズムでは,ページに直接ジャンプする行動に対応する項のベクトルの要素値(以下の式の第2項)は,すべて\(\frac{1}{N}\)としていた. このベクトルを調整することで,特定ノードの影響を強めてPageRankの値を補正することができる.
Q3のPageRankの計算にて,直接ジャンプ項のベクトルの要素値について,
賴山陽,本居宣長,杉田玄白,関孝和に対応する値は\(\frac{1}{4}\)に
上記人物以外についてはゼロ
になるように設定し,再度PageRankを計算し,その値の上位30位の人物を求めなさい.
ヒント: NetworkXのpagerank関数を用いず自力で行列計算で行う場合は,賴山陽,本居宣長,杉田玄白,関孝和の値がベクトルの何番目に対応するかを調べる必要がある.